A topic
This new topic is added…
TPAC 2025
Kobe, Japan & online
10–14 November 2025
The main question I hope to address: I've got a programming language that translates to all the others. You can write a library and get a JavaScript library, and another for Python, and another for C#.
How might it help deliver standards?
How might it help the developers downstream?
How might it help the tool ecosystems that arise around standards?
How might it help smooth work between W3C groups?
Just to get something out of the way early. This is not an AI talk. If you like AI talks, that's cool, but everything I'm talking about here is done with compiler methods.
First, I'm here presenting the work of the Temper contributors.
But so you all know whom you're talking to.
My primary focus is programming languages, developer tools, helping developers make better, more reliable systems.
I started in programming languages about 30 years ago at CMU's field robotics center.
I've done web stack stuff, notably on Google Calendar, an early JavaScript heavy web application. I wrote large chunks of the first frontend, and I was the internationalization lead during Google's internal forty languages initiative.
I've done standards work before: Calconnect briefly, TC39 for a long time. Most recently, in W3C I helped with an early version of the trusted types spec.
And I spent over a decade in security engineering. I was one of the non-cryptographers; I approached security from the perspective of how better tools, for example, XSS-safe template languages, help developers produce more secure systems.
And now, I am the language designer for Temper Systems.
So if you're here at TPAC focused on internationalization, the web stack, security, distributed systems, or developer tools; I can probably relate to some of the challenges you deal with.
⇒ Why a translating language?
Demos: making standards easier
What do you, standards' maintainers, need?
Designing for Translation
State of the Project
I want this talk to be interactive, so jump in with any questions. First, some background and demos to set the stage.
Then I'd like you all to drive the discussion. What would you do differently if you could deliver libraries to every language community?
Then, if there's interest in programming language design, I have prepared some remarks on what you do differently to get high-fidelity translation.
Finally, I can give an overview of the state of the project. You can use it today. But being an early language adopter comes with challenges. If this sounds useful to you, we, the Temper team, would love to work with you to mitigate early-language adopter pains and can help out with implementation work.
A programming language
Most programming languages run in one or a few runtimes. For example, Java on the JVM.
Temper is designed to translate well; to run in all the runtimes.
Our focus is on libraries that support programs. A person who understands a problem really well should be able to solve it by writing a library that supports every PL community.
Our target audience is everyday programmers. The language looks superficially like TypeScript so it's easily recognized.
And we work by translation. There's no virtual machine barrier. When you define a class in Temper, and use the Python translation, it's just Python classes and objects all the way down.
And its our goal to support standards efforts. Both W3C style and smaller efforts inside organizations; anything that smooths collaboration between subject matter experts and software practictioners.
Data scientists use Python/Julia/R.
Web uses JavaScript/TypeScript.
Backenders use typed PitL PLs.App devs use Kotlin/Swift/Java (Dalvik).
Microservices, stateful async functions, do not solve all problems.
Let me explain the motivation for this project.
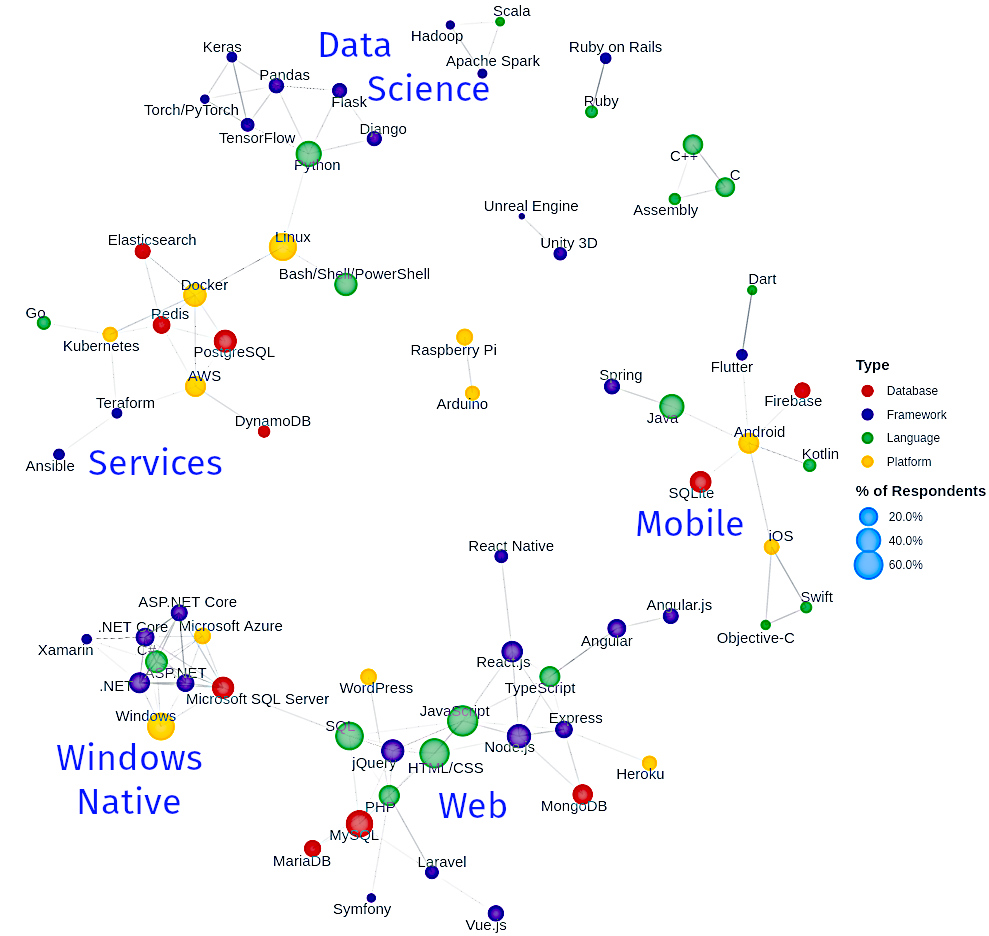
Here's a diagram from Stackoverflow's 2020 developer survey.
We've got a lot of technology stacks; a lot of programming languages and frameworks.
That's great! Developers can choose the right tool for the job.
But it comes at a cost: disconnected language islands.
(The blue labels are mine) You can see here that data scientists cluster at the top: Python, TensorFlow.
They use different stacks than mobile app devs on the right: Kotlin, Swift, Dart
The web platform which we all know and love is at the bottom.
And backend developers tend to use a typed language like C# or Java.
What we need, a new way of sharing:
Single source of truth, ubiquitous libraries.
This leads to a number of problems.
The same code gets written in multiple languages. An estimated 30% of engineering effort is wasted on this.
Or you use a micro-service; sometimes that's appropriate. But if you're using a micro-service because you want to share logic, you've just added network delay, and a point of failure.
In practice, the inability to share across language boundaries leads to multiple implementations. But not every language needs the whole thing, and why would you port tests for parts you don't need. You end up with multiple, poorly tested, inconsistent, partial implementations.
And because there's no shared definitions, static anlyzers, code quality tools, can only look at one node in one language. Analyses stop at the island shore.
Temper enables a new mode of sharing, type definitions and logic, whole libraries, among every node in a multi-language system.
A developer using Temper can solve a problem for every programming language community.
Focus effort on one implementation, one source of truth. Amortize testing and documentation across all the language communities.
And from the engineering management side: an alternative to "every teams owns a service in production", is "some teams own a library or standard that supports many other teams"
So maybe you're in one island and I'm on another.
If we realize we have a common problem, we should be able to express a common solution.
But that requires a language. My motivation for this project was make that language.
I want deep thinkers to be able to solve problems for everyone.
Maybe you really understand a problem like HTML sanitization, taking untrusted HTML and turning it into trustworthy HTML. If you write a solution in C#, you've solved it on one island. But that doesn't help Lua users.
So Temper's value proposition is a bit different. This is not a language you use instead of other languages, you use it alongside to support.
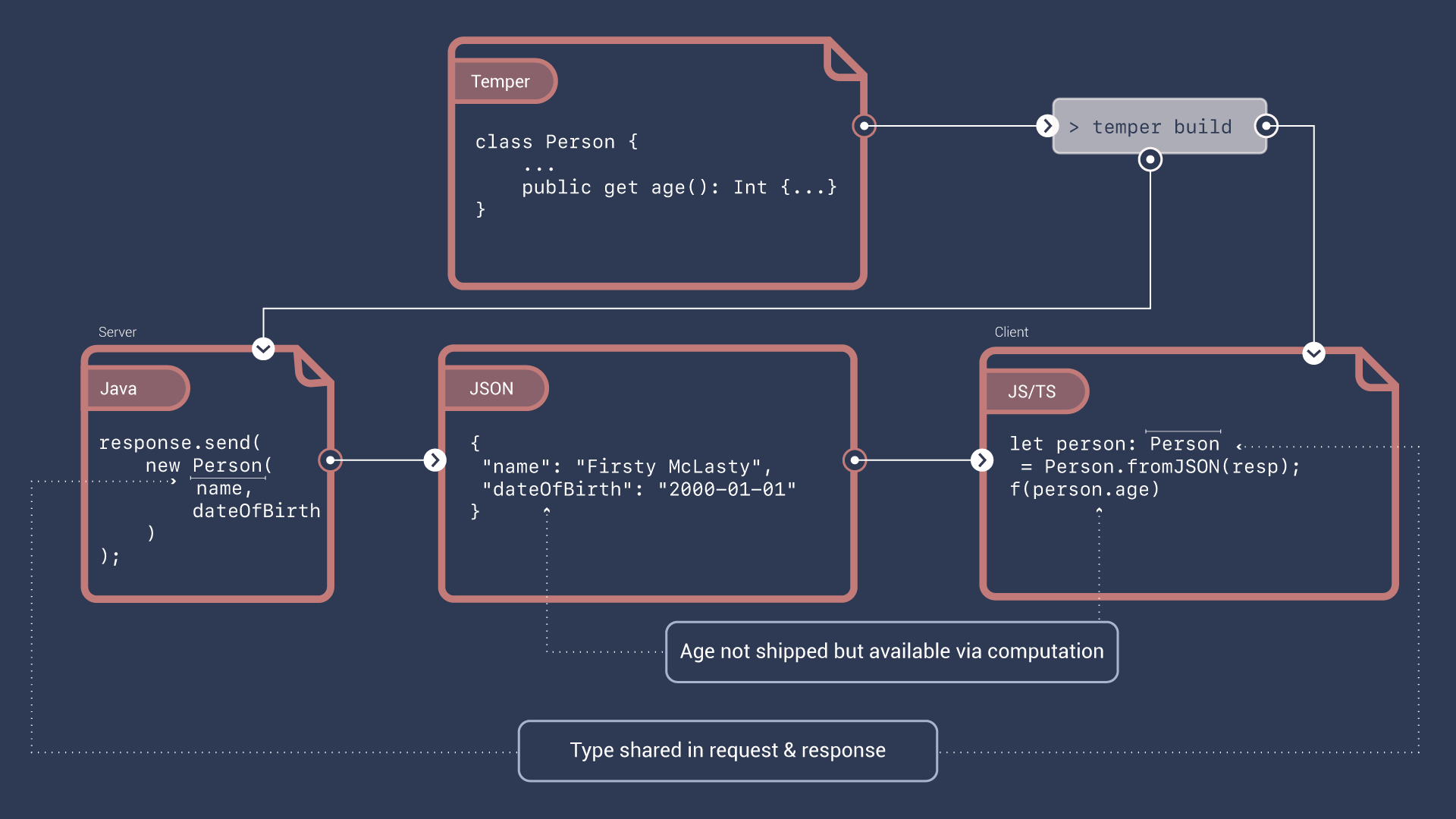
But the island analogy works not just for language communities, it also applies to systems. Here we've got a Java backend talking to a JavaScript web client. Those are also islands.
If we can share type definitions within a system, then you can extend a degree of type safety across network boundaries. Here, a class, Person, is shared between Java and JavaScript by translation, but the two also share logic, encoders for values to and from JSON. And by sharing a computed property definition, your wire format becomes concise; we don't need to send the age back and forth because we can compute it anywhere.
And going back to static analysis, now static analyzers have common points of reference.
Why a translating language?
⇒ Demos: making standards easier
What do you, standards' maintainers, need?
Designing for Translation
State of the Project
So that's the motivation and project goals. Next up, demos.
A literate specification with types, logic, and tests.
Can delivering libraries with specs help devs and the dev-tools ecosystem?
Avoid interop problems via a partial reference implementation.
I've got a few demos prepared. Depending on what interests people, I can skip around.
The first is a simple one. A literate standard that mixes prose, reference implemenation code, and tests. I want to show what it's like to use the language, and what the reference implementation looks like.
The second, CSS colors. Browsers care about CSS colors, but so do graphic designer tools. I was hoping to frame discussion about how a standard could encourage a rich tool ecosystem by making colorspace logic ubiquitous.
Third, the JSON standard. There are a lot of parsing corner cases that cause interop problems. Could those have been avoided if just part of the specification were ubiquitously available?
Literate Temper code in Markdown
Prose intermixed with type definitions, logic, and tests
Using the playground to see libraries from target language users' points of view.
Demo script:
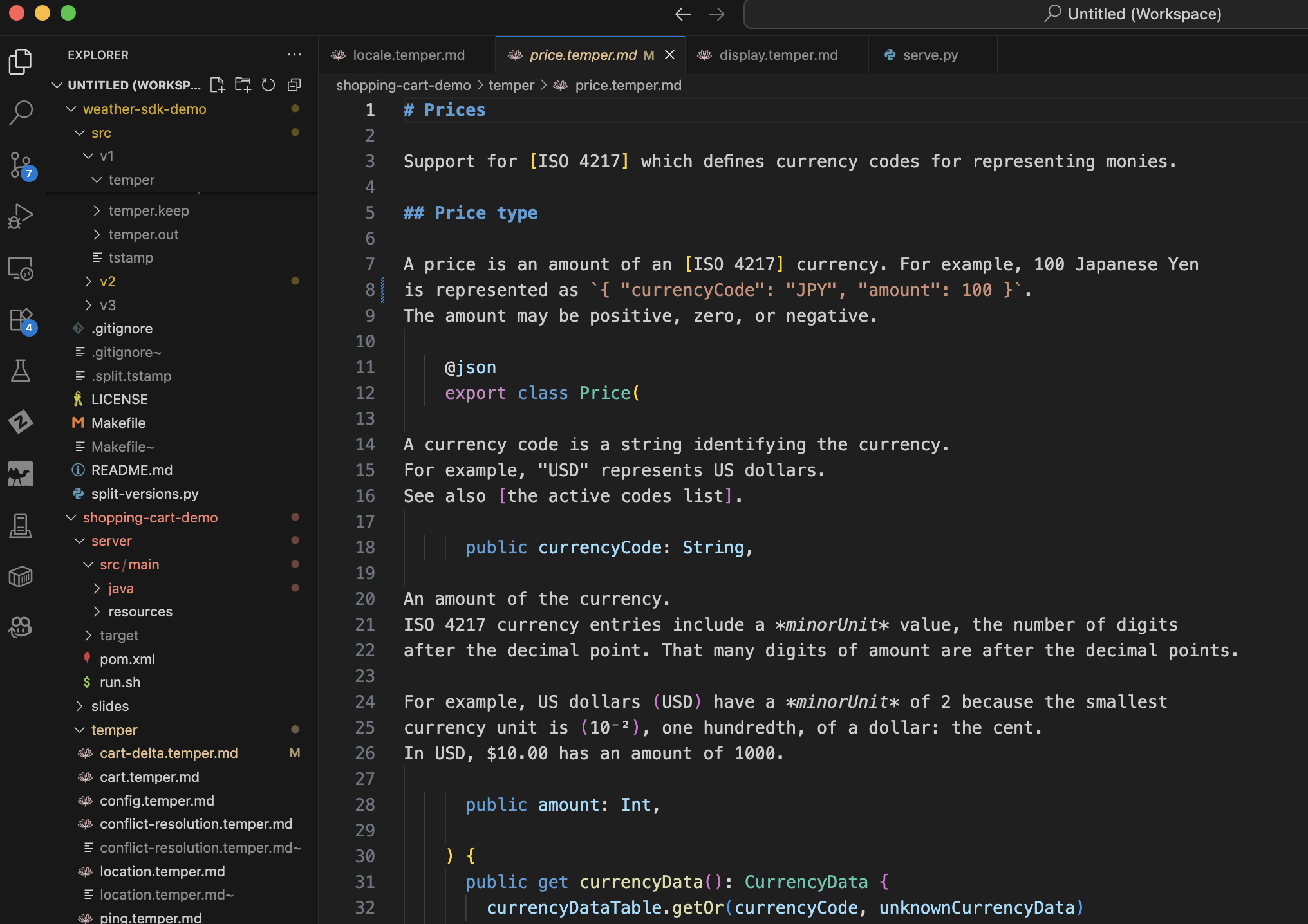
-- show price.temper.md in VSCode.
Here's Temper source code embedded in Markdown, literate style.
And we define a price class here.
The prose explains how the currencyCode and the amount relate to one another.
-- scroll to L20
And here we're explaining how minor units affect the amount.
So we explain what we're doing in prose, and how to do it in code.
-- scroll down to toString
We've got some logic here to format a price as a human-readable string
-- scroll to test at L70
And down here we have examples as unittests
So the narrative structure here is "here's what we're doing, here's code, how we compute what needs computing, and for example, unit tests.
-- temper repl -b py
temper repl dash b py starts up a python REPL, a playground, with the Temper libraries loaded. Let me import what I'll need
from cart_demo import Price
from temper_std.json import JsonTextProducer
help(Price)
Here's the docs for the Price class. You can see it's just a regular Python class. I can create a price, 1000 yen
p = Price('JPY', 1000)
p.to_string()
It formatted nicely using the conventions from the price data table in the ISO.
json_out = JsonTextProducer()
Price.json_adapter().encode_to_json(p, json_out)
json_out.to_json_string()
And we can encode a price to a JSON value using our logic which means we can send values from one language using Temper to another.
-- temper repl -b java
Switching over to Java. Let met copy/paste some imports.
import temper.std.json.*;
import com.example.cartdemo.*;
Price p = new Price("JPY", 1000);
Price.jsonAdapter().decodeFromJson(JsonGlobal.parseJson("{\"currencyCode\":\"JPY\",\"amount\":1000}"), NullInterchangeContext.instance)
$4.getClass()
I created a price, and it formatted using the formatting logic in the literate spec.
And I can decode the JSON from Python if I wanted to demo a whole server setup.
And when I inspect the decoded JSON, it's a Java object whose class is the Price type.
Show unpacking a value and how it's just a regular Java class.
-- look in temper.out/java/cart-demo/
We've got a pom.xml here. We generated the source translations and also the package metadata to support the whole java tool chain.
-- bat temper.out/java/cart-demo/src/main/java/com/example/cartdemo/Price.java
Here's the translation of the Price class into Java. Our translation is just a regular Java class and you can see some of the documentation from the literate spec attached here that flows through to javadoc.
-- bat temper.out/java/cart-demo/src/test/java/com/example/cartdemo/CartdemoTest.java
-- search for priceFormat
We translate not only the production code. Here's a translated file under src/test, where maven expects unit test files.
We translated the unit tests to Java too. Test code tends to be pretty formulaic; less room for mistranslation. So even though this is a new language, test coverage will give you confidence in the translation.
Single source of truth for SMEs and implementors.
Devs end up with a library.
Every PL community gets supporting libraries and can exchange values with others. Islands bridged!
Here's what I hope you noticed:
In a standards document, we explained things in prose, so it's accessible to subject matter experts. Embedded code captures how computation is done, and tests.
One thing to note: tests are pretty formulaic, so subject matter experts should be able to capture some requirements, as they figure things out, as tests, possibly with AI assistance, and hand them off to implementors.
At the end of the standards drafting process, mormally, that's when the hard work for implementors starts. But in this case, you've got a well-tested reference implementation ready.
With Temper, you deliver high quality support to devs and bridge those language community islands.
Demo…
-- Show css-color-4 in VSCode
The target audience for the CSS colors module is browser implementors, but there's an entire ecosystem outside the browser. Graphic designers need tools to author and refactor CSS, design systems people, CSS generating DSLs in the Markdown publishing space, and tools like CSS minifiers.
The nice thing about libraries is that you can provide conveniences. What is the named color closest to a color, and how close is it, in the OKLab space or the RGB space? This function answers that.
-- cd examples/csharp/ColorPick; dotnet run
Here's a simple C# Avalonia app that I can load an image into.
-- Load w3logo.png, click some points
I click a point, and it shows the color in the RGB space but it also shows the closest named number in the Oklab and RGB spaces.
-- Show css-color-4/examples/csharp/ColorPick/ColorPick.csproj
Many developer tools are not written in a web language entirely, so might implement their own partial, divergent implementations.
Here's the C# project file. Here it depends on the Temper output directory for the translated color library code because we have not published this to nuget.
-- Show css-color-4/examples/csharp/ColorPick/MainWindow.axaml.cs
This is the app code that handles user events. Scrolling down to OnImageClick. Towards the bottom, we're calling out to the Temper translation of the NamedColors code to find the closest. So a Temper reference implementation supports tools development in C#.
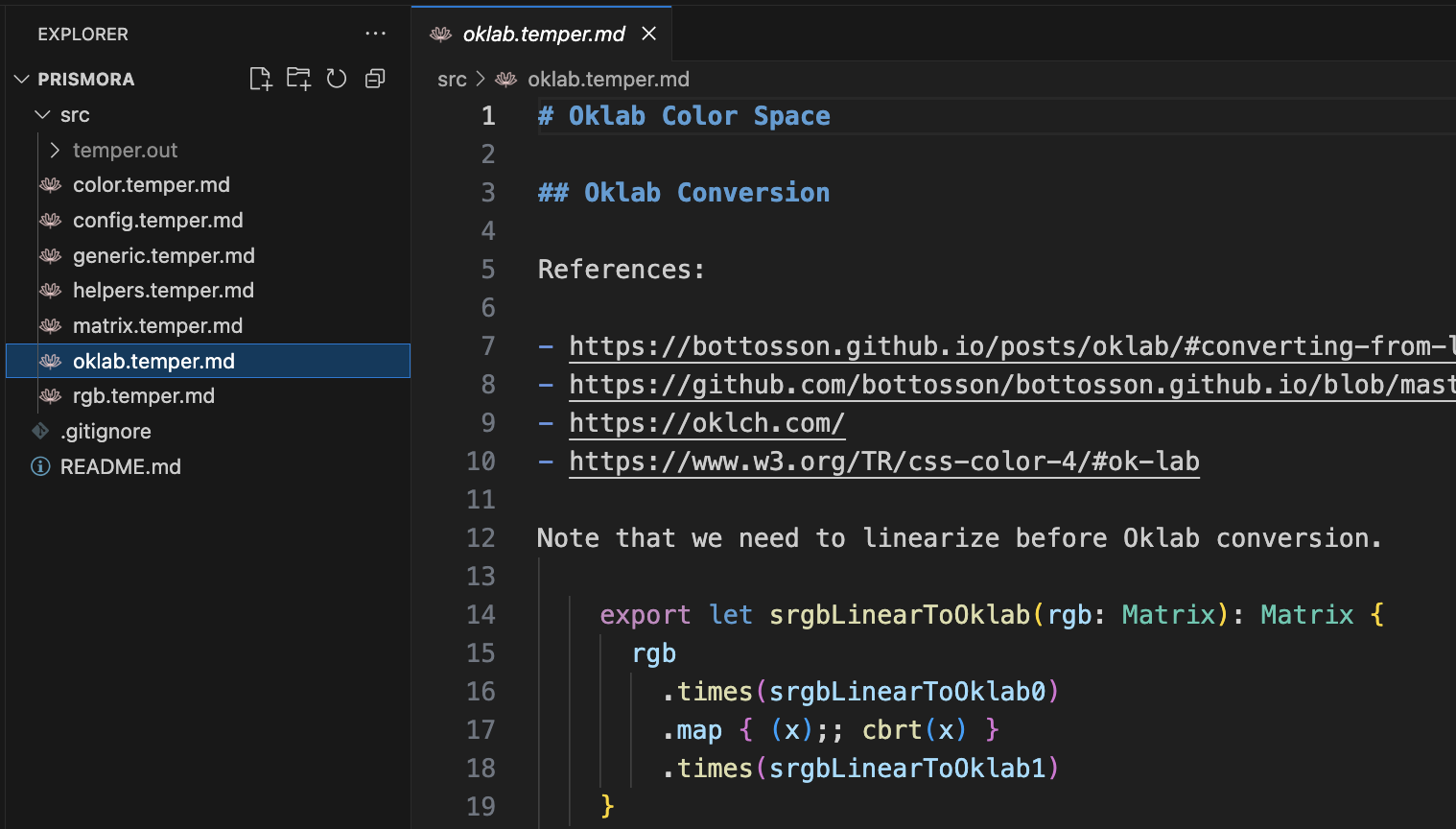
-- Show css-color4/src/conversion.temper.md
If you're familiar with the colors spec, this'll look familiar.
It's got a bunch of colorspace conversion utilities.
And if I scroll down, these are all bottoming out on some matrix math.
-- Show css-color4/src/named.temper.md
And here is the CSS named color list, but if I scroll down, you'll see it turned into a code list.
One thing we could do for literate Temper is a bit of metaprogramming, a macro that can map over rows in an HTML or markdown table to turn it into values.
-- Show css-color4/src/tests.temper.md
Here's tests for our implementation. These get translated to
unit tests in C#, so you get confidence in the C# translation by
just running dotnet test.
Many potential users not using a web platform PL:
Library-driven interop good for the tools ecosystem.
Easier to evolve a spec when the tool ecosystem quickly catches up.
Obviously, there is already a thriving CSS tool ecosystem.
It have been easier to bootstrap if Temper had been available?
Today, might it be easier for the CSS colors maintainers to evolve the spec if the tool ecosystem could track parts of it by just doing a library update?
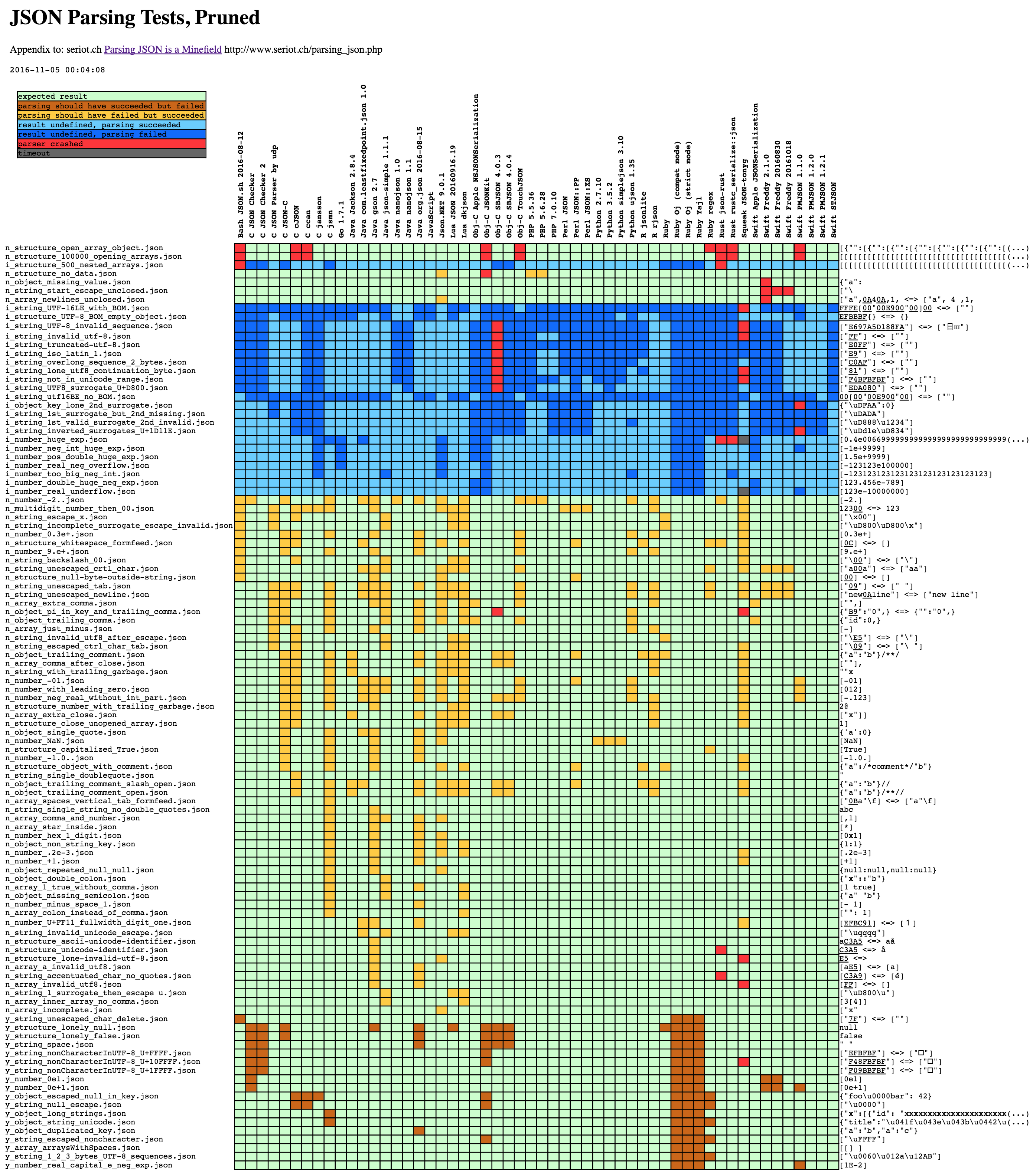
Lots of interop problems around parsing
What resulted: an undocumented de facto standard for a "safe" subset† of JSON syntax.
With Temper, this could have been avoided.
† superset of a subset, aka :shrug: relationship
Parsing JSON is a minefield. It really is.
I did a bunch of work on JSON security starting around 2008, so this hits me hard.
That image is a test result matrix. Each row has a snippet of JSON, some invalid.
Each column is a JSON parsing library.
The whole point of a format like JSON is, two programs, often in different languages, agree on the format, and then they can communicate.
But there's a lot of disagreement, a lot of parsing corner cases. There're reasons for that.
This all could have been avoided if the json.org, RFC 8259, and later ECMA-404 had the tools to provide a partial implementation of the JSON parsing algorithm.
Problem: JSON agnostic to number/string representation, value semantics.
[1,2] could specify a list of 32b ints, or big
decimals, or a 2-D point, …
Can we implement enough JSON once to solve interop but remain value-semantics agnostic?
JSON is an interop format. It has numbers and strings, but it doesn't say what they mean, nor should it.
And the relationship between JSON sub-expressions and values is incredibly context dependent.
Here, [1,2] could mean a list of 32 bit ints, or of big decimals, or a 2 dimensional point.
If Temper were available when JSON was first drafted, could we have dodged the all these parsing interop issues while leaving the value semantics to the application code that has the context?
![A sequence of three labeled diagrams. First label 'Source Text' above code '[1, 2, 3]'. Second label 'Abstract Syntax Tree' above one box labeled 'Array' that fans out to three boxes below labeled 'Number(1)', 'Number(2)', 'Number(3)'. Third and last diagram, 'Flattened Tree / Event Stream', above 'startArray, number(1), number(2), number(3), endArray'. From the Array box in the middle diagram, two dashed arrows fan out to the 'startArray' and to the 'endArray' events. One dashed arrow goes from the 'Number(1)' box in the second diagram to the corresponding 'number(1)' text in the third. There are two labels to the right of the second diagram: 'Inner Nodes' lining up with the 'Array' box and 'Leaf Nodes' lining up with the 'Number(...)' boxes.](parsing-with-event-streams.png)
Among security engineers, I was known as that guy who does strange things with parsers.
I'd like to show you a useful trick: event-driven parsing.
It allows representing both parsing and unparsing operations as a stream of events. Conceptually, it involves flattening an abstract syntax tree to a list: each inner node becomes a tagged start and end node, and content lives at leaf nodes. But because each event corresponds to a method call, it's flexible and performant. There's no need to build a tree in memory.
Solution: value-model-agnostic event-driven parsing and unparsing à la SAX.
![a sequence diagram consisting of a vertical stack of four nodes each pointing to the next. From top to bottom, in order, 'parse("[[123]]")', then header 'Event Stream' above 'startArr, startArr, number(123), endArr, endArr', then ValueBuildingEventReceiver, then 'listOf(listOf(123))'](json-parsing-pipeline.png)
![a sequence diagram consisting of a vertical stack of four nodes each pointing to the next. From top to bottom, in order, 'serialize(listOf(listOf(123)))', then header 'Event Stream' above 'startArr, startArr, number(123), endArr, endArr', then JsonTextProducingEventReceiver, then '"[[123]]"'](json-unparsing-pipeline.png)
Event-driven parsing allows a very clean separation between structure and semantics.
How does that simplify parsing and unparsing?
As can be seen on the left, we can have a generic JSON parser, one which cares nothing about the values it produces, convert JSON text into an event stream.
The knowledge about how to turn those events into a value is embedded in an event consumer.
The reverse is also possible. An encoder for a type can serialize a value to events. A generic JSON stringifier consumes those events, adding tokens to an output buffer.
Let's look at Temper's std/json library which does this.
Demo…
-- Show std/json/json.temper.md
Here's part of Temper's standard library. We implemented JSON support including auto-deriving encoders and decoders.
-- Scroll to interface JsonProducer L37
Here, a JSON producer receives events.
For example, to encode an object record, you start an object, then you issue a key event, and a sequence of events for the value, and finally after the last property you end the object.
-- Scroll down to parseJsonValue L764
Here's the workhorse parsing method. It takes the text, a location in the text, and the producer, and it issues events and then returns the start of the still unparsed portion. And you can see it looksahead by 1, classifies the next token and then delegates to a more specific parse method.
-- Scroll up to JsonTextProducer L365
As I explained earlier, unparsing uses the same machinery.
JsonTextProducer is a JsonProducer that composes a JSON text.
-- Scroll up a bit to the state machine comment L356
Internally, it models a state machine so it knows when to insert commas and colon tokens.
-- Scroll down a bit to `var wellFormed`.
And it keeps track of whether its well-formed; if it gets an odd sequence of events, then it sets wellFormed to false to indicate that the content it has appended to its internal buffer might not be a prefix of a valid JSON text.
-- Scroll down to booleanValue L453
Here we force a state transition before a value. If we're in a non-empty array, that'll output a comma so we're ready for a value.
Sometimes a full reference implementation is impractical.
Partial implementations can achieve specific goals:
e.g. interoperability, buffer-overflow/eval safety.
Be opinionated where helpful, agnostic where not.
Often, there are library design strategies that separate concerns.
The takeaway from this JSON example: you don't need a full implementation to provide a lot of value.
There may be good reasons not to do a full reference implementation. But often there are strategies to be opinionated where it helps and agnostic where it doesn't.
In this case, the community would have benefitted from consistency in string processing; once we identified that need, the design flowed naturally from that.
Different audiences for libraries:
I showed you three demos.
I want to spur ideas on how the Temper language can help standards folk in their work, and the developers and software downstream.
The thread tying these demos together, each looks at supporting a different group of contributors.
Everyday developers, browser&tools developers, or framework authors.
But I also think there's an opportunity for you to help each other. If some other W3C group has questions about what you're doing and how it affects them, giving them a reference implementation that works in the languages they use might help.
You all would probably know better than me, what that'd look like.
Why a translating language?
Demos: making standards easier
⇒ What do you, standards' maintainers, need?
Designing for Translation
State of the Project
I'm here representing the Temper contributors, and would love to know what we can do for you, and I can make committments of aid.
So opening this up, how this might help you in your work?
Why a translating language?
Demos: making standards easier
What do you, standards' maintainers, need?
⇒ Designing for Translation
State of the Project
Next up, what makes Temper different from other programming languages?
Why do you even need to design to translate well? Why not just translate an existing language?
Many multi-backend languages run in their runtime, and JavaScript runtimes: Scala, OCaml, Dart, Kotlin.
But not Python
Scala tried and abandoned .NET support
Temper: a language without a runtime.
Designing to translate well requires specific choices: …
There are languages that extend beyond their runtime.
Lots of languages work by translation into JavaScript.
JavaScript is a dynamic language; it's easier to interoperate when you don't need to work within its type system.
But those same languages haven't taken the next step and interoperated with Python.
Scala runs in the Java VM. C# is very similar in many ways, but not close enough for Scala to be able to run in a .NET runtime despite significant effort.
Temper is a language without a runtime; it works by translation into other languages so works in many runtimes.
Next, I'd like to give you glimpses into the design space.
Now is the winter of our discontent
Made glorious summer by this sun of York
- Shakespeare
Sun of York.
Son of York: King Edward IV
Embedded assumption:
Sun and son sound the same in English.
What complicates translation? I'm going to list a few things. I'll start off with a natural language example, and then show code that has a similar difficulty. This isn't meant to be exhaustive, just illustrative of the kind of surprises that await if you try to take an existing programming language, one not designed to translate well, and then naively translate it.
As an example of an embedded assumption, here's a famous passage from Shakespeare:
Now is the winter of our discontent; made glorious summer by this sun of York.
There's a pun there. With an 'o', son of York refers to Edward the fourth who was raised in York.
That pun won't translate easily to languages where the correpsonding words don't sound the same, for example the French fils et soleil don't.
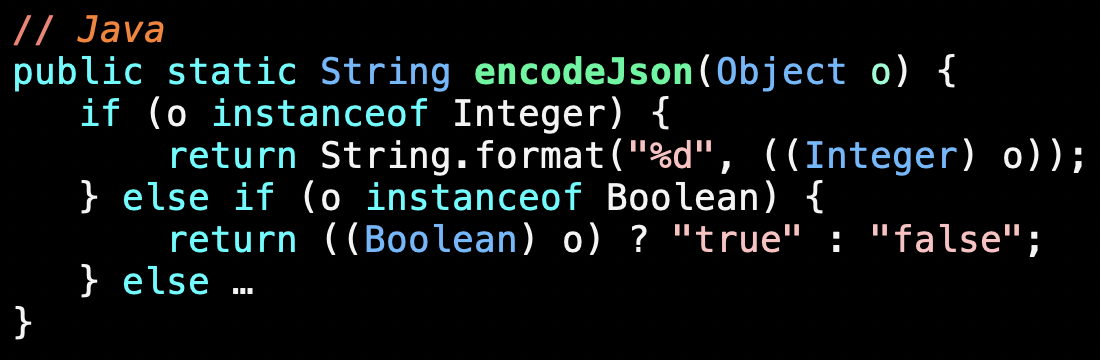
Embedded assumption:
In Java, no Boolean is an Integer.
But in Python, every bool is an int.
Here's a fragment of code with an embedded assumption.
It encodes a value as JSON. If o is an integer, it formats as decimal.
Otherwise, if o is a boolean it returns the keyword.
But there's an order to those instanceof checks. The Java version works because the first test will fail if the second succeeds. There's an embedded assumption, true in Java, that booleans are not integers.
Python got a distinct bool type around version 2.3 or 2.4, but until then people just used 1 and 0 for true and false. Python already had a "not" operator that returned an int. Rather than introduce a new "not" operator they just reused the old one but it changed from returning ints to returning ints that are also bools. In Python, every bool is an int.
In English, you may include honorifics: "Mr. Fred Rogers," or you can omit them: "Fred Rogers."
In idiomatic Japanese, you must include honorifics, e.g. -san.
In English, you must specify a subject: "It is windy." What is windy? I don't know. It is just there because English requires a subject.
A translator must synthesize missing, required elements.
Next complication: in almost any language, you can express a given idea, but in some, you have to express certain other things.
For example, in English, you can specify honorifics: Mister or Mrs. Often you don't.
In Japanese, it's unidiomatic to leave them out.
And in English some things, subjects and articles, are required.
A translator must synthesize missing, required elements. In the case of honorifics, this might require researching the relative status of the speaker and the addressee.
In Java, you may specify optionality:

In Rust, you must:

This shows up in code. In Java, you can specify whether an input is optional; whether you can pass in null if you don't care. In Rust, you must. There is no null singleton so you need to use an option type.
| German | English |
|---|---|
| Geist | ghost |
| Zeitgeist | spirit of the times |
Geist can often translate to ghost.
But you can't say the "ghost of the times" in English.
"Spirit" can mean essence, but "ghost" conveys disembodied-ness.
Sometimes, there's a really good translation for a term. English Ghost and German Geist are cognates.
When you translate Zeitgeist from German into English, you need to use the English word Spirit, a Romance language borrow, because Ghost has additional connotations, namely a ghost is a disembodied spirit.
Python: 
JavaScript: 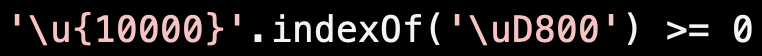
Does one string contain another as a substring?
Strings are a workhorse type. Ideally they'd have the same semantics across languages.
They do not. Not even close. Because variable-length encodings.
Here's an example of checking whether a surrogate is a substring of a supplemental codepoint. That's true for JavaScript and false for Python.
We put a lot of very careful work into getting efficient, reliable semantics for strings in a way that's familiar to developers.
Ad-hoc types: tuple types, arrow types.
Value identity / pointer equality (haecceity): ===.
(Wait! You thought computer scientists couldn't invent problems with no analogue in human language?!)
More complicators.
Yes, we computer scientists have come up with problems that would shock professional linguists. Go us!
In nominal types, for two types to match, they must be defined in the same place.
But ad-hoc types, combine other types. If those other types are combined in the same way, they match.
Strangely ad-hoc types break dependency management.
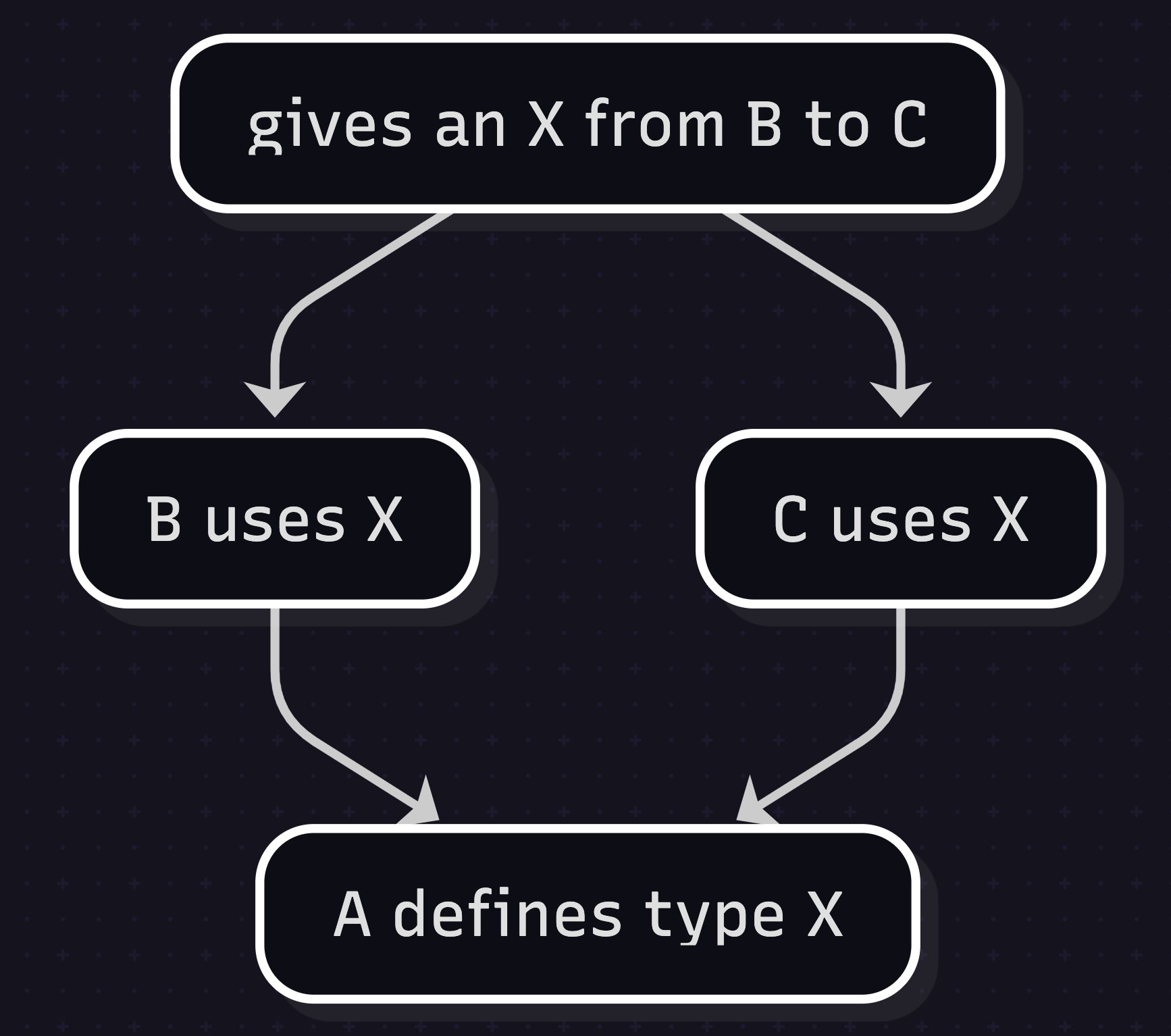
Ad-hoc types cause problems when you need to translate to a language that does not have ad-hoc types.
The problem is this. In a nominally typed language, every type is declared somewhere. The bottom node, A, declares a type. Then B and C both import and use that declaration. That means D can use B and C together.
With an ad-hoc type, there may be no A to which the separate translations of B and C refer. This is a problem for translating D to use both.
Scala and Kotlin have worked around this fairly successfully, but the solutions have drawbacks.
Goal: Idiomatic way to represent optional inputs, unavailable outputs, or not-computed-yet intermediates.
Goal: Translate to Option types or null singleton where idiomatic.
Complicator: Some(None) ≠ None but when using a singleton it is.
Solution: use null semantics but restrictions on generics mean when translations to Option types never produce nesting Options.
Moving to specific design decisions:
Null, everyone's favorite billion dollar problem.
Actually the problem was unchecked null, which Temper checks.
Programmers need some way to represent optional inputs, unavailable outputs, and often intermediate values that are not yet available.
There are two main approaches to that in modern languages: null and option types
These two are not equivalent, because the singleton null hides an ambiguity.
We have to interoperate with both languages, so Temper has a null singleton, but type checks nullity. And we do some additional static checks that affect type polymorphic code, so that it's impossible to write Temper code that trips over that ambiguity.
This is just one example of the kind of thing that trips up languages that define semantics for their runtime, and then try to expand outside it. But we planned ahead.
Goal: Idiomatic way to represent and recover from failure.
Translate to exceptions, or Results as appropriate.
Go: extra output, OCaml/Rust/C++: Results, others: exceptions
Complicator: exceptions, non-local transfer of control. Don't want to catch and rethrow repeatedly.
Solution: Result semantics but results are not first class; user code cannot use a Result type for local variables / inputs / fields.
Error handling. If a function realizes it's not going to be able to produce a usable result. For example, it's parsing a number but the string is malformed or a file is unreadable. When that happens it needs to hand control to code that can try to recover or try a different strategy.
Exceptions are a common way to do that in modern languages.
But if you're familiar with Rust or Go or OCaml, then you're familiar with Result types.
Error handling is super important. If you don't support a language's preferred way of handling errors, then you're failing users who are working within that paradigm to write reliable code.
Result types are a principled approach to error handling. It turns out that if you don't treat them as first class, these restrictions here, then you can provide good support both to languages that have them and to languages that use exceptions.
Goal: Consistent semantics for basic operations
| comparison | 2 < 11 && "11" < "2" |
|---|---|
| stringification | "${1.0}" == "1.0" |
These should distribute through generic containers:
"${ [0, 1] }" != "${ [false, true] }"
Generic operations. A generic operation is one where the type of an input affects part of the operation, but often most of it doesn't depend on the type.
As you can see here, the less-than operator is generic. It can apply to numbers or to strings. When applied to numbers, it does numeric comparison. When applied to strings, it does lexicographic comparison.
And when we convert a floating point number to a string, we want some consistency.
But some dynamic languages don't make the distinctions I just outlined.
Complicator: Some languages (e.g. Perl, PHP, JavaScript) do not distinguish between all of ints, floats, booleans, strings. 0 can mean different things.
Complicator: Cannot trust RTTI because can connect multiple Temper types to one target language type.
Solution: Type reification that desugars provides just enough trait-like dispatch, and threads through generic programs.
Notably, Perl, PHP, and JavaScript do this. Perl and PHP have a scalar type that covers numbers, strings, and booleans. JavaScript has a number type that is used for all floating point computation, and most integer computations.
That means we can't have one comparison function that looks at the type of its arguments. Not only does the performance suck, but there just isn't enough information at runtime.
That's our solution. We solved this problem because we had to by repurposing a number of well-understood PL techniques. But existing languages just won't because they grew up alongside a runtime that mandated a behavior. Sorry that the solution uses a lot of jargon, but I'm happy to explain offline.
But because we solved this, developers can rely on an intuitive semantics.
Goal: timely deallocation even for programs written by non-systems-language users.
Goal: common OCaml discipline (immutable records) just work.
Complicator: Important languages do not have garbage collection that handles cycles: C, C++, Rust, Swift
Linear type discipline requires a high-skill level.
We want people to be able to write Temper libraries that don't leak memory even if they're not familiar with memory pitfalls in C++ AND Rust AND Swift.
Our target audience is not just people skilled at manual memory management.
But we need to translate to those languages which require some care because they don't have cycle-safe garbage collectors.
Solution: Make generic programming harder to make non-generic programming easier. Static checks enforce points-to analysis to which prevent object-graph cycles making ref-counting sufficient for timely deallocation.
Between immutable records, that which is older cannot point to that which is younger.
This was a tough call. There's no make-memory-easy option.
What we ended up with is a bit different, but it keeps the burden on more specialized library developers who maintain core, generic libraries.
We added static checks to class declarations and to type parameter bindings.
class Cons<F -| Cons<F>>(public hd: F, public tail: Cons<F>?) {}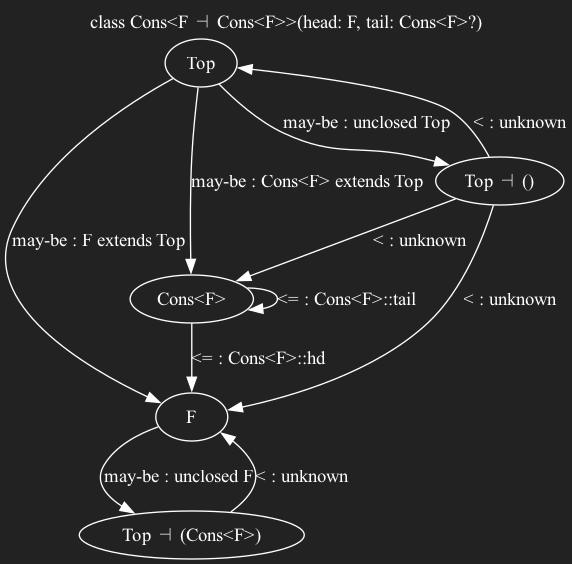
Here's a recursive data type, a simple Lisp-style Cons list.
Each type involved has a node.
A Cons points to its head and tail.
A Cons instance's tail has to be older than it, so the loop there is all less-than edges.
A Cons's head could point to something that points back to itself, so the programmer has to put some extra limitation. That sideways tack means F can't bind to something that points to a Cons<F>.
class Cons<F -| Cons<F>>(public hd: F, public var tail: Cons<F>?) {}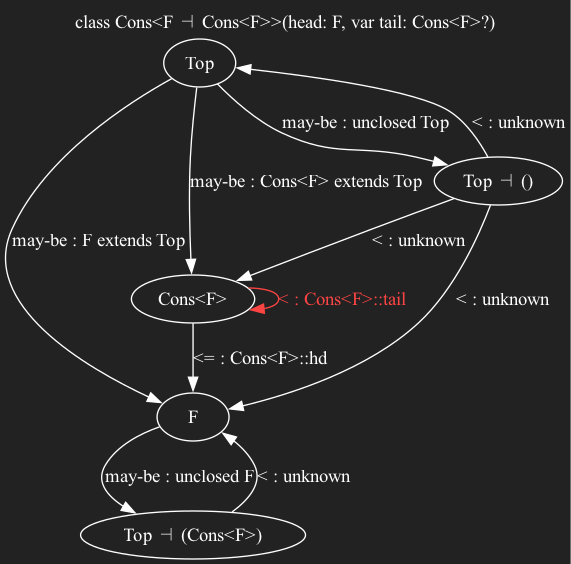
But if we made the tail mutable, then a cons list could be relinked to create a cycle, note the less-than-or-equals edge.
This kind of cycle analysis just works for standard OCaml record style, but requires extra, implementation-detail leaking restrictions for generic types.
The basic idea here is: if the less-than edges don't form a cycle, then there exists an order in which reference-counted records will destruct. But if node has to be less-than itself, a contradiction, then there is no order and we don't know that it'll deallocate.
Goal: safe usable concurrency. Do not consume resources (system threads) for every outstanding network message.
Complicator: in some runtimes, pointer assignments are not
atomic.
Not all languages expose threads. Not all runtimes have support
for coroutines. Ugh, GIL.
Work queues are widely available on non-threading runtimes, and
can be implemented using threads.
Coroutines are sufficient to
await promises.
Concurrency lets a programmer compute an answer without controlling the order in which everything happens; I will need an answer to this sub-problem. I'll start it now, but I don't care whether it happens before or after this next thing, as long as I have the answer when I need it.
Widely used languages have a lot of different takes on concurrency.
Unfortunately, concurrency done wrong can lead to memory corruption.
So Temper can't put the safety burden on developers; our target audience isn't just people who know how to avoid unsafe pointer writes.
Our solution here is really just, figure out what familiar, safe abstraction can we cobble together on a runtime that has at least one of these widely available affordances.
Work queues can handle stepping a coroutine that awaits a
satisfied promise.
The in-process actor model allows mutually
exclusive access to shared resources.
Solution: Optionally implement state-machine coroutine
conversion during pre-translation.
No non-thread-safe top-levels (except in REPL).
Statically declared & checked, Imu
and PartialImu and Sharable
and PartialSharable type modifiers allow safe communication
across parallel contexts.
So we can provide coroutines, and we can provide promises, and they work pretty well together.
And we put some restrictions on global, mutable state to ensure safety.
What does myString[i] mean? What even is a "character"?
| Rust | index by UTF-8 code unit | |
| C++ (usually), Lua, Go, OCaml | index by octet, usually UTF-8 | |
| C#, Java, JS | index by UTF-16 code unit | |
| Python3 | index by codepoint | |
| Ruby | yes! we do those things! | |
| Swift, Temper | indices at CP edges by construction |
Strings are a workhorse datatype. They need to work consistently. It's really hard to translate string processing code consistently across languages.
What does it mean to get the i-th "character"? What even is a character?
You can see in this table, languages fall into two main groups, but there's a lot of variation. Some PLs are byte-based, the first two rows, and some are UTF-16, byte-pair based. Python is codepoint based.
Temper arrived at the same approach as Swift, which allows it to provide a consistent code-point based semantics, like Python, but to be efficient on other runtimes.
// Up casts: to more general
myCat as Animal
// Safety known during compilation.
// Down casts: to more specific
myAnimal as Cat
// Safety can only be checked at runtime.Complicator: type introspection, RTTI not consistent across PLs.
Type systems that allow sub-typing can over specify or under specify types at different times, and casting lets developers work around those limitations of the type system.
The problem is that only upward casts can be known safe at compile time. And when casting is safe is often subtle. Temper developers shouldn't have to know multiple languages subtleties around casting to write safe code.
Unfortunately, not all languages provide enough information to test whether a cast is safe before it happens.
Complicator: Some languages (e.g. Perl, PHP, JavaScript) do not distinguish between all of ints, floats, booleans, strings. 0 can mean different things.
Solution: Restrictions on down-casting. Sealed (sum) types always castable.
If this complicator looks familiar, it is. This came up when discussing basic generic operations like comparison. Sometimes multiple Temper types are represented using the same target language type. In many runtimes, it just doesn't make sense to ask "is this a boolean or an int?"; the answer is a "yes."
So we have a lot of restrictions on casting.
But we do relax that. A sealed type, a kind of sum type where the compiler has access to all direct subtypes, allow the compiler to bake in extra code to enable safe checks. So casting from a sealed type to a direct subtype is checkable.
This is a common pattern. Constrain what developers can write so that we know we can reliably translate it. But then provide a familiar affordance from other languages so that developer's have a way to do what they need and can build on their experiences with popular languages.
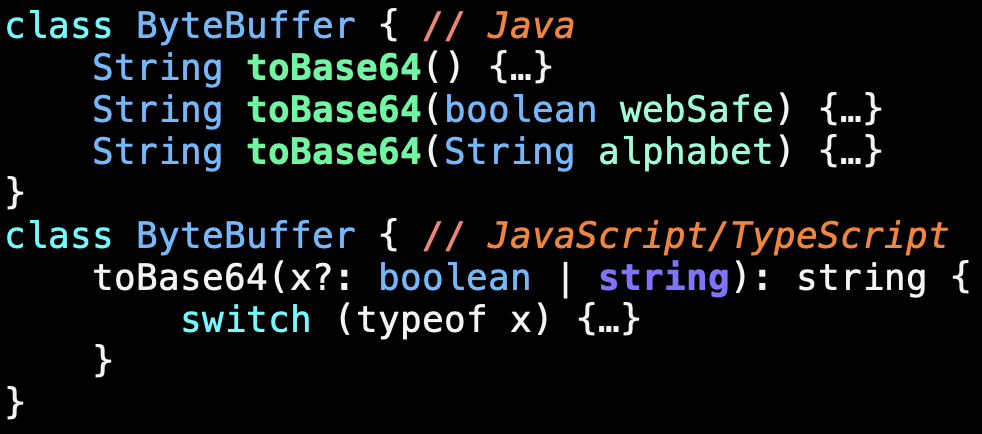
Here's a class with some methods in Java, and then something similar in JavaScript.
Maybe when converting bytes to base 64, there's a default zero argument version of the `toBase64` operation, and two other variants.
Good library design requires providing conveniences, and overloading is one way to do that.
In the Java on the top, we've got three overloads: three methods with the same name distinguished by different argument types.
But in dynamic languages, like JavaScript, at the bottom, that doesn't work.
In typed languages, static dispatch works; overloading works. In many dynamic languages, all dispatch is static.
Goal: allow groups of related, overloadable dispatching while working on backends that allow no overloading.
Solution: Call-site overload resolution in language.
Stable names allow checking whether two declarations are the same between version 1.0.0 of a library and version 1.2.3.
It's very convenient to give every method a distinct name.
But we use cues and metadata to group methods together.
Backends receive method groups, not just methods, and can choose to present them as overloads or not. We have a way to store historical information, information about the choices made when translating a particular published version, so a backend can store information about what it did based on the language's signature collision requirements and later runs of the compiler can use that to make backwards compatible choices.
Why a translating language?
Demos: making standards easier
What do you, standards' maintainers, need?
Designing for Translation
⇒ State of the Project
Finally, the state of the Temper project
Six years of work
Lots of competing requirements.
But there's a nice, usable language in the middle,
familiar
to everyday programmers.
We've been at this for six years.
Two years just understanding the problem space.
Four implementing the compiler frontend and backends.
There are a lot of competing requirements. It's not obvious that there are non-interfering solutions.
But I think we've got a nice, usable language. It's getting to be fun to work in.
Implemented initial set of backends to test different language families
| C# | Java: legacy 8, modern 17 |
JavaScript with TS comments |
| Lua | Python3 with mypy types |
Rust |
| In progress: | C++ and some older languages | |
|---|---|---|
| Researched: | C, D, Dart, Elixir, Go, Julia, Kotlin, OCaml, Perl5, PHP, R, Racket, Ruby, Swift, Zig | |
I've said things like "translates to all the languages."
Here's the list of languages we support today, and the list that we've done some prep work for.
One kind of cool thing: we have an opportunity to do dual-mode libraries: translate to Python, but implement compute intensive functions in C++ so if you import into Python, and it can use native functions, it links them in. Otherwise it falls back to the pure Python version.
There's a similar story for JS and Wasm.
| ✓ | Stable syntax | ✓ | Backend infrastructure |
|---|---|---|---|
| ✓ | Reference documentation | ✓ | Command line tools |
| ✓ | VSCode Plugin | ✓ | Standard Library |
| ✓ | Playgrounds | ~ | Static Checks |
| ~ | Type System | ~ | Backward compat checks |
| TODO | Incremental compilation | TODO | Stable version metadata |
| TODO | Library repository | TODO | Next dozen backends |
Programming languages go through stages.
We're in the early adopter stage.
We've got the language functional. It's usable today, but we are reworking some significant parts, like the type system, in significant ways based on what we learned. Most of those changes should not affect backwards compat, but we're taking the opportunity to make sweeping changes now.
And we're still working on things like, how do we store information about compilations so we can do less work on incremental compilations.
And we've got plans for a library repository, like pypi but for Temper.
Can make breaking changes now!
Interested? → W3C interest group
Want help trying out Temper for your standard? We can help!
So we can make breaking changes now.
If you need something from us to make Temper an awesome language for supporting standards work, let us know.
If you'd like to be part of an interest group, I'd love to chat.
And if you have an idea about how to spec something related to your standards work, we might be able to pitch in with advice and/or implementation work.
TPAC 2025
Kobe, Japan & online
10–14 November 2025
Notes for slide 2 can be put here.
 Metro pole
Metro poleNotes.
Words can be given a strong emphasis, which makes them appear in bold
The normal emphasis has a highlighter effect.
Code looks like this: if (a) return b;
This link goes to slide 2
This is an example of a note, in a smaller font
Notes.
Unfold (default style)
Fade in (class=emerge)
Notes.
Quick
(class=quick)
Fade in + red items
(class="emerge strong")
Notes.
Quick + greeked
(class="quick greeked")
Fade in + red + dim (class= "emerge strong dim")
Notes.
Combining class=incremental with class=in-place yields elements that are displayed one by one, with each one replacing the previous. Example:
| X | ||
| O | ||
| X | ||
| X | O | |
| X | ||
| X | O | |
| X | ||
| O |
| X | X | O |
| X | ||
| O |
| X | X | O |
| X | O | |
| O |
| X | X | O |
| X | O | |
| O | X |
(class=overlay is an alias for class=incremental.)
Notes.
A slipshow presentation is one where you don't put each topic on a separate slide, but add it to a long scroll, which automatically moves up to display it.
The idea is by Paul-Elliot Anglès d'Auriac, see his program on GitHub.
B6+ supports a simple version.
This slide is an example.
Just progress (with space, arrow, click or swipe) to display additional topics.
This new topic is added…
When there is no more space, old content moves up…
| Column head A | Column head B |
|---|---|
| A table | Just as an example… |
| A2 | B2 |
| A3 | B3… |
The space for the list is reserved…
One more bit of content…
And a final one.
Notes.
It seems the famous ‘lorem ipsum’ is based on a text by Cicero, but with the lines mixed up. On a Cicero by the text, it seems the ‘ipsum lorem’ is famous based with lines but mixed up.
Notes.
And again, with class slide side right.
It seems the famous ‘lorem ipsum’ is based on a text by Cicero, but with the lines mixed up. On a Cicero by the text, it seems the ‘ipsum lorem’ is famous based with lines but mixed up.
Notes.
![[Top view of four pairs of hand holding each other crosswise]](https://www.w3.org/2018/Talks/TPAC-2018/ceo-update/diversity.jpg)
Adding class cover to the image makes it stretch to
the edges of the slide.
Notes.
And also on the right side…
Hint: Add class=clear on the slide to omit the banner and slide number.
Notes.
It seems the famous ‘lorem ipsum’ is based on a text by Cicero, but with the lines mixed up. On a Cicero by the text, it seems the ‘ipsum lorem’ is famous based with lines but mixed up.
Notes.
And again, with class ‘slide side right big’.
It seems the famous ‘lorem ipsum’ is based on a text by Cicero, but with the lines mixed up…
Notes.
It seems the famous ‘lorem ipsum’ is based on a text by Cicero, but with the lines mixed up. On a Cicero by the text, it seems ‘ipsum lorem’ is famous based with lines but mixed up.
Notes.
And on the right side…
Notes.
The description of the pie chart, here as a table:
| Name | Percentage |
|---|---|
| Andy | 16% |
| Chloe | 21% |
| Daniel | 13% |
| Grace | 20% |
| Sophia | 30% |
Notes.
Children of an element with a class of columns are
distributed over two columns
This is the second child, which goes into the right column
And this is the third one. Left column again.
Etc.
Notes.
Notes.
Lines in a PRE can be numbered
(automatically)
* Give the PRE a class of "numbered"
* Works for up to 20 lines
(depending on font size)
six
seven
eight
nine
ten
eleven
Notes.
| row 1 | has no background |
| row 2 | has a gray background |
| row 3 | has no background |
| row 4 | has a gray background |
| etc. | |
| etc. |
Notes.

Careful, some images make the text hard to read!
Notes.
Careful, some images make the text hard to read!
Notes.
![[photo with a beach, cliffs, buildings, dark clouds and a surfer]](https://www.w3.org/2020/Talks/ac-slides/template/coast.jpg)
slide darkmode for
white-on-black(Photo ‘Surfer and the stormy sea’ by Xavier Nohet)
Notes.
Shout:
Takahashi method!
Shout & Grow:
Animated
Notes.
The style sheet predefines several transitions:
A transition can be set globally, applying to all slides;
or locally, applying only to the transition between this slide and the next.
Notes.
If the text doesn't fit, and you really cannot reduce it nor split the slide, you can ask b6+ to scale the text down until it does fit.
To do this, add class textfit to the slide.
Too much text…
Too much text…
Too much text…
Too much text…
Too much text…
Too much text…
Too much text…
Too much text…
Too much text…
Too much text…
Too much text…
Too much text…
The last line.
Notes.
Print in portrait mode to get:
Notes.
Notes.
This is a template for slides for TPAC 2025. It uses either the Shower script (version 3.2) or the b6+ script for the presentation. (To enable Shower, uncomment the script tag in the HTML source.)
If you cannot put them online yourself, you can download a zip (see below) with everything needed to develop slides offline and ask Bert Bos for help uploading the slides once they are ready.
Writing slides online (with JigEdit, WebDav or CVS) is only available to the W3C team. Make a directory under https://www.w3.org/2025/Talks/TPAC/. Copy the Overview.html from https://www.w3.org/2025/Talks/TPAC/Templates/ into your directory and edit the content, or just use it as an example.
If you develop your slides offline (or plan to present them without a network), then download this zip file. Unpacking it creates the following directories and files:
Make a directory for your own slides under TPAC-2025. You can copy the Overview.html file there as a starting point, or just use it as an example. If you make any images, put them in that directory as well.
If you are able to upload your slides, put your directory with all that it contains under https://www.w3.org/2025/Talks/TPAC/. There is no need to upload the Templates directory. It is is already there.
Each slide is a section element* with a class of slide:
<section class="slide"> ... slide content here... </section>
Inside the slides, use normal HTML elements (p, ul, em, etc.).
*) Note for advanced users: Although not shown in this template, it is in fact possible to use other elements than section. One common choice is div.
You can add additional text, such as speaker notes or explanations, between the slides. They will be visible in index mode but not in slide mode. Use elements with a class of comment:
<section class="comment"> ... text here... </section>
If a slide should not have a slide number and an image banner, add the class clear:
<section class="slide clear"> ... slide content here... </section>
On title slides, this only removes the number, not the banner.
Adding the class clear on the body element omits the slide number and the side banner from all slides.
For cover slides (the title slide or separator slides between parts of a presentation), add a class cover. You can combine cover and clear. E.g.:
<section class="slide cover clear"> <h1>My presentations<h1> <address>Peter W. Slidemaker</address> </section>
The class final is meant for a last slide, e.g., for conclusions or thanks (but it may be used elsewhere, too):
<section class="slide final clear"> <h2>Conclusions<h2> … </section>
Slides with narrower text and an illustration on the left or right can be made by adding the class side to the slide. Inside the slide there should be exactly one element that also has a class of side (an image or some other element). Two sizes are possible: normal (about 1/3 of the slide) and big (about 2/3 of the slide).
To put an image on the left:
<section class="slide side"> <img src="..." alt="..." class="side"> ... slide content here... </section>
To put the image on the right instead, add class right (which may be abbreviated to r):
<section class="slide side r"> <img src="..." alt="..." class="side"> ... slide content here... </section>
Add class big to the slide for a bigger image. To put the image on the left:
<section class="slide side big"> <img src="..." alt="..." class="side"> ... slide content here... </section>
And on the right:
<section class="slide side r big"> <img src="..." alt="..." class="side"> ... slide content here... </section>
The image can be stretched to the edges of the slide by adding a class cover. The image is not deformed. It is scaled to be big enough to cover the image area and then either the sides are cropped (if it is too wide) or the top and bottom*.
<section class="slide side big"> <img src="..." alt="..." class="side cover"> ... slide content here... </section>
*) Note for advanced users: It is possible to indicate which sides should be cropped: add an attribute like style="object-position: 20% 60%" to indicate that, of the amount to be cropped from the sides, 20% should be cropped on the left and the remaining 80% on the right; and of the amount to be cropped from the top and bottom, 60% should come from the top and the remaining 40% from the bottom. Thus, e.g., ‘0% 100%’ says never to crop anything from the left (0%) if the image is too wide, and only to crop from the top (100%) if the image is too tall. (The default corresponds to ‘50% 50%’, i.e., crop equal amounts from both sides.)
When information is in the form of an image (a diagram, a chart, a screenshot, etc.), put it inside a figure element. Add a figcaption if needed.
<figure><img src="..." alt="..."><figure>
If the image is not accessible, use a details element instead and add a description, like this:
<details> <summary><img src="..." alt="..."></summary> ... the same data as in the image, but as text... </details>
The description becomes visible when the user clicks on the image. (The slide above shows an image of a pie chart that is described by a table with the same data.)
Setting the class autosize on an image instructs b6+ to scale down the image if the slide's content is otherwise too tall:
<img src="my-image.png" alt="..." class=autosize>
You can have several images with class autosize on a slide and they are all scaled down by the same percentage.
If you want a progress bar during the slide presentation, add an empty div with a class of progress. It can be put before the first slide or after the last, but there should be at most one such element in the file:
<div class="progress"></div>
The progress bar will show as a thin red line along the bottom of the slides. Its length indicates the position of the current slide in the slide deck.
B6+ also sets a custom style variable --progress with a value between 0 and 1 on the body. This may be useful if you write your own style rules for a progress indicator.
To progressively reveal elements on a slide, put a class of next on all elements that should not be visible right away. They will become visible one by one as you press the space bar or an arrow key. E.g.:
<ul> <li>This item is visible when the slide appears <li class="next">This item is not immediately visible <li class="next">This is the third item to appear </ul> <p class="next">This is the last element to appear
By default, each new element appears with a short animation as if it unfolds from left to right. Two alternative animations are available: emerge makes the elements fade in and quick omits the animation. The class can be set on each incremental element:
<li class="next emerge">...
or on an ancestor, e.g.:
<ul class="emerge"> <li class="next">...
Three optional modifiers change how elements look before, after or while they are the currently active element: Strong makes the currently active element red. Greeked replaces the elements that are not yet visible by a gray bar. (Useful to show how many elements are still invisible.) And dim grays out the elements that are no longer the active element.
Like the animation, these modifiers can be set on the incremental element itself or on an ancestor. The modifiers can also be combined, e.g.:
<ul class="emerge strong dim"> <li class="next">...
With b6+ (but not with Shower) you can make slides that have more incremental elements than fit on the slide. To display them, the slide automatically scrolls to each element as it is revealed.
This mode of presentation is called a ‘slipshow’ by its inventor, Paul-Elliot Anglès d'Auriac. (His program is on GitHub.) B6+ only implements a simple variant.
Scrolling slides may be useful for long content or when you want to add content while keeping some of the preceding content on screen. (An alternative is updating elements in place.)
Slides can be made to advance automatically after a given time, by setting a data-timing attribute on them with a value of MM:SS (minutes and seconds), or a number followed by an s (seconds), m (minutes) or h (hours), e.g.:
<section class="slide" data-timing="1:03"> <section class="slide" data-timing="20.5s"> <section class="slide" data-timing="0.33m">
E.g., the last one means that the slide is shown for a maximum of 0.33 minutes (about 20 seconds) before the next slide appears. (You can still advance the slide by hand before that.)
If the slide contains incremental elements, the time is distributed equally over those elements. E.g., if there are three incremental elements, the time is divided by four so that the first incremental appears after a quarter of the given time, the second after half the given time, and the last one after three quarters. You can also set a time on an individual incremental element, in which case that time is used for that element. E.g.:
<section class=slide data-timing="8s">
<p>This slide has 3 incremental elements.
<ol>
<li class=next data-timing="10s">Shown after 8/4 = 2 seconds
<li class=next data-timing="15s">Shown 10 seconds later
<li class=next>An additional 15 seconds later
</ol>
</section>
After 29 seconds (= 2 + 10 + 15 + 2), the next slide will appear.
You can set a default time on the body element, e.g.:
<body data-timing="20.2s">
This sets the time for all slides that do not have a data-timing attribute of their own.
Setting the data-timing attribute to 0 indicates that the slide or element does not automatically advance.
To put elements side by side in two columns, make an element (a div, ul or any other element) with class columns. The first child of that element will be put in the left column, the second child in the right column. If there are more children, the third will be in the left column again, the fourth in the right, etc.
<ul class="columns"> <li>First goes on the left</li> <li>Second goes on the right</li> </ul>
Less important text can be shown in a smaller font by giving it a class of note:
<p class="note">Note that this is harder to read</p>
To make text extra big, give it a class of shout, e.g.:
<p class=shout>Hurray!
(Sometimes this is referred to as the ‘Takahashi method’: Instead of sentences or graphics, a slide only contains one or two keywords. The narrative comes from the speaker.)
To draw extra attention to some text or an image, it can be animated. Adding a class of grow to it will make it appear slowly. It will start small and one second after the slide appears it will begin to grow and reach its normal size three seconds later.
<p class=grow>See?
B6+ can automatically reduce the font size of a slide to fit long text. To request this, add the class textfit on a slide (or on the body, if all slides need this). See the example slide.
(The way this works is that b6+ wraps the contents of the slide in a div with the right font size. If you have added your own style rules, make sure they still work.)
Be careful! The textfit feature can easily result in text that is too small to read.
Pre-formatted text (in a pre) can be given line numbers by adding the class numbered:
<pre class="numbered">
No more than 20 lines will be numbered. (In the normal font size, a slide fits 13 lines.)
To replace the list bullets with icons, emojis, or images, make a ul with a class of with-icons. The first element of each li will be used instead of the list bullet.
<ul class=with-icons> <li><span>♪</span> North pole</li> <li><img src="../Icons/toc.png" alt="toc button"> Metro pole</li> </ul>
It is possible to treat the slide as a 3×3 grid and put elements in the four corners, in the middle of each edge, or in the center of the slide. This is done by giving the elements a class of place. On its own, place puts the element in the center. By adding classes top, right, bottom and left the element can be placed in one of the eight other positions.
<div class="place">Put this in the center</div> <div class="place bottom">Put this bottom center</div> <div class="place top right">In the top right</div>
The direction classes can also be abbreviated to t, r, b and l.
To put an image behind the text of a slide, use an img with a class of cover:
<img class="cover" src="..." alt="...">
The image will be stretched to fill the whole of the text area. If the image doesn't fit exactly (wrong aspect ratio), the image will be cropped.
With a class of fit instead of cover, the image will be scaled but without cropping. Instead there may be white bands on the sides or above/below the image, if it doesn't fit exactly.
<img class="fit" src="..." alt="...">
This works both for normal slides and title slides (slides with a class of cover). The slide number is not obscured by the image. (But you can use clear on the slide to hide it.)
It is advisable to add a class of darkmode or lightmode to a slide with an image overlay. See the next section.
The colors of the slides depend on whether ‘dark mode’ is in effect in the operating system: slides have black text on a white background if dark mode is off and white on black if it is on. But when text is overlaid on an image, it may be better to force the text to always be white (if the image is dark) or black (on a lighter image). You do that by setting a class on the slide: darkmode (for white-on-black) or lightmode (for white-on-black). E.g.:
<section class="slide darkmode">
Other colors (titles, list bullets, links, etc.) also become fixed on such slides.
To make all slides white on black, set the class darkmode on the body element. In that case you can use the class lightmode on individual slides to give them black-on-white text.
Some images, such as diagrams, can be color-inverted and still look good. You can give such images a class can-invert and when the slides are displayed in dark mode, the image colors will be inverted. (Try it on the slide with a figure.)
<img class="can-invert" src="..." alt="...">
This also works for SVG images and other things.
Videos (with the video element) and audios (with the audio element) on a slide can be made to play automatically when the slide opens, by giving them an autoplay attribute, e.g.:
<video src="myvideo.mp4" autoplay></video>
Videos can be used as background for the slide with the cover or fit classes. (See their description under ‘Image overlays’.) The class fit is also useful simply to make the video as large as possible if it is the only thing on the slide.
However, if you do use one of those classes, it is best to use the autoplay attribute and to avoid the controls attribute, because the video controls will capture all key presses and mouse clicks and thus you can't use those to advance to the next slide anymore. (If you do want to use controls, either present with a second window (see below) or set a data-timing attribute on the slide, so that it advances to the next slide automatically after a given time.)
By default, each slide just replaces the previous one, but there are several predefined slide transitions. You can set a transition on the body element to apply it to all slides:
<body class="shower fade-in">
Or you can set it on individual slides, to apply only to the transition between that slide and the next. (I.e., it doesn't determine how the slide appears, but how it disappears.)
<section class="slide wipe-left">
You can set both a global transition and local ones. The global transition applies to slides that do not have an explicit transition set locally.
When you present while using a screen reader, you cannot use the screen reader's usual keystrokes to navigate, only the keystrokes defined by the b6+ script. However, the screen reader will speak each slide as soon as it appears. The script creates an element with attributes role=region and aria-live=assertive for that purpose.
When you leave slide mode, the screen reader will say ‘stopped’. To make it say something else (e.g., because you want a different language than English), create an element with role=region and aria-live=assertive yourself and put the text to speak in it. E.g.:
<div role="region" aria-live="assertive">
Terminé.
</div>
The slides can be exported to PDF (or printed) in two ways: multiple slides per page with comments interleaved, or one slide per page without any comments. The latter may be useful to create a PDF suitable for presenting, when it is not possible to use an HTML browser.
Note: In landscape mode, the style sheet tries to set the size of the output page to exactly the size of a slide, but not all user agents that produce PDF respect that. (And, obviously, a printer is limited to the available paper.) There may be some black margin to the right and below each slide. Prince does respect the size. W3C team can also use the ",pdfui" tool online.
To present the slides, load them into a browser that supports JavaScript and CSS and then either click the play (▶) button, press the A key, double-click on a slide or touch the screen with three fingers (on certain devices).
If you are using Shower instead of b6+, press Shift+F5 (Command+Enter on Mac) or click on a slide.
Navigate though the slides by clicking the left mouse button, pressing the spacebar, the arrow keys or Page-up/Page-Down. The Home and End keys jump to the first, resp. last slide. F1 or F toggles full screen mode. C shows a clicakble table of contents. The ? (question mark) key shows a list of available commands.
If you have automatically advancing slides, you can pause the slide show with the P key or the Play/Pause key, if your keyboard has it. You can also navigate to a different slide and resume from there.
To exit the presentation, press the A key or the Esc key.
For more keys, see the documentation for keys & gestures in b6+ or keyboard shortcuts in Shower.
While in slide mode, you can press the D (only with b6+) key to switch between black-on-white and white-on-black. (This temporarily adds or removes the darkmode class on body, see ‘Forcing white text or black text’.) When the computer is already in dark mode, the key instead switches the slides to light mode (and adds the class lightmode on the body).
B6+ (but not Shower) can show the slides in a second window. The first window can then be used to control the slide show and view notes and next slides. If you have two screens that can show different content (e.g., your computer's screen and a projector), you can thus present the slides on one screen, and preview the next slide and any notes on the other.
Open the second window by pressing the 2 key, or the ⧉ button in index mode.
After pressing the W key, you can draw on the current slide with the mouse. Press W again to clear the drawing.
The drawing is not permanent and there is always only one slide with a drawing: As soon as you start drawing on another slide, the previous slide is cleared.
The color of the drawing can be set with style rules, e.g., like this:
.b6-canvas {color: red}
When using a second screen, it is possible to show clocks on the first screen with the remaining time, the time used so far, and the real (wall clock) time. (The clocks are normally only shown on the first screen, but they can be included in slides or overlaid on slides, by adding suitable markup and/or CSS rules.)
By default, the clocks will count down from 30 minutes and show a warning 5 minutes before the end. (In the style used for this document, the clock turns from green to orange.) You can set different times with the following classes:
To set the duration to, e.g., 45 minutes,
add duration=45 to the class attribute of
the body. Example:
<body class="duration=45">
To set the warning to, e.g., one minute, put this in the class of the body:
<body class="warn=1">
B6+ has two kinds of clocks built-in, but also provides primitive elements with which to build your own clock.
To get one of the built-in clocks, make an empty element with a class of either fullclock or clock. The former will display the real (wall clock) time, the number of minutes so far, the number of minutes left, a small ‘pie-chart’ showing the proportion of time used, and four buttons: subtract one minute, add one minute, pause the clock, and reset the clock. The simple clock will display the pie chart and the four buttons (somewhat smaller) and the remaining minutes.
When you make your own clock, you can make use of the following classes and attributes:
B6+ will fill all elements with a class of hours-real with the current hour (wall-clock time) and keep them up to date. The hour will always be two digits and use a 24-hour clock: 00 to 23.
Similarly, all elements with a class of minutes-real or seconds-real will contain the current minutes or seconds, respectively, also always as two digits, 00 to 59. E.g.:
<b class=hours-real>00</b>:<b class=minutes-real>00</b>
Elements with these classes will contain the time since the slides where loaded (or since the clock was reset, see timereset below). E.g.:
<b class=minutes-used>00</b>'<b class=seconds-used>00</b>"
Ditto, but for the time still remaining. If the used time exceeds the duration, these times will be shown as 00.
An element with a class of timeinc will act as a button that increments the duration, and thus the remaining time, by one minute. timedec decrements the duration by one minute. E.g.:
<button class=timeinc>+1 min</button> <button class=timedec>−1 min</button>
An element with this class acts as a toggle to pause & resume the clocks. When the clocks are paused, the used time does not progress and the remaining time does not diminish. (The real time clocks continue, of course.) When the element is clicked again, the clocks resume. E.g.:
<button class=timepause>pause</button>
An element with this class acts as a button to restart the clocks, i.e., to set the used time to zero. Example:
<button class=timereset>reset</button>
In addition to setting the time in elements with the classes mentioned above, b6+ also updates the style property, the class and a data- attribute on the body. This is useful for style rules to change the styles of elements based on the progress of the slide show. In particular, b6+ sets the following:
Add ‘?full’ at the end of the URL (but before any fragment ID) to open the slides in slide mode instead of index mode.
To open in slide mode at a specific slide, add ‘?full’ and the ID or the number of the slide, e.g., Overview.html?full#place or Overview.html?full#20.
When you don't want the mouse pointer to remain on the screen in slide mode, add the class hidemouse on the body element. If the mouse does not move for 5 seconds, the pointer is made invisible. It comes back as soon as the mouse is moved.
<body class="hidemouse">
You can also set a different timeout in seconds. E.g, to set a short timeout of 1.5 seconds:
<body class="hidemouse=1.5">
Normally, a mouse click anywhere on a slide (other than on a hyperlink or form element) has the effect of advancing to the next slide or incremental element. If you don't want that, add the class noclick on the body element.
<body class="noclick">
You can embed a single slide in another document with the help
of an <object> or <iframe>
element. To avoid that a keypress or click
accidentally changes the slide, you can disable navigation
and index mode: add ‘?full&static’ at the
end of the URL, followed by ‘#’ and the ID or number of the desired
slide. E.g.:
<object data="Overview.html?full&static#18">...</object>
or
<iframe src="Overview.html?full&static#18"></iframe>
Adding ‘?static’ on its own to the URL is also possible: It shows all slides in index mode and disables switching to slide mode.
Note that using ‘?full&static’ on an automatic slide show plays the whole slide show without the possiblility to pause it.
The page ‘Speaking guidelines’ of the TPAC 2025 site contains recommendations for presenters.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
This is a template for slides for TPAC 2025.
Author(s): The user manual at the end has setup information and instructions. To write slides, look at the slides in this template.
Reader(s): To start the slide show, press ‘A’. Return to the index with ‘A’ or ‘Esc’. On a touch screen, use a 3-finger touch. Double click to open a specific slide. In slide mode, press ‘?’ (question mark) to get a list of available commands. To start the slide show, press Shift+F5 (Command+Enter on Mac). Return to the index by pressing ‘Esc’. You can also click to open a specific slide.
If it doesn't work: Slide mode requires a recent browser with JavaScript. If you are using the ‘NoScript’ add-on (Firefox or the Tor Browser), or changed the ‘site settings’ (Chrome, Vivaldi, Opera, Brave and some other browsers), or the ‘permissions for this site’ (Edge), you may have to explicitly allow JavaScript on these slides. Internet Explorer is not supported.